マテリアルズ・インフォマティクスにおける回帰係数・変数重要度の分析
本記事の概要
この記事では、機械学習を行った際の変数重要度・回帰係数の分析について解説していく。理論系ではなく、実装を主に書いていく。言語はPython、ライブラリはscikit-learnを使用している。pythonの基礎を習得した方向けの内容となっている。”マテリアルズ・インフォマティクスにおける〜〜”と言う記事題名にしておきながら、この辺の方法はマテリアルズ・インフォマティクスに限ったものではなく、機械学習一般における実装になる。
記述子の解析
線形系の予想モデルの回帰係数や決定木系のモデルの変数重要度を確認することが可能である。これによって、重要な変数だけを抽出して次の回帰の参考にすることも可能であるし、どのような変数が聞いているのか推測することもできる。マテリアルズ・インフォマティクスでは主に後者の方が重要かもしれない。とりあえず、今回は回帰係数・変数重要度の確認の仕方を解説していく。
回帰係数
回帰係数による解析は、非常に簡単であり、イメージつきやすいのでそれほど説明は不要であると思う。 回帰係数の絶対値が大きければ、重要な変数であることは間違いないし、変数の値が正になっていれば目的変数と正の相関があるなどといった具合である。
この回帰係数で変数の分析を行う場合は、スケーリングを事前に施した記述子を使用する必要があるという点に注意が必要である。これは、大きなスケールで変動する記述子と小さなスケールで変動する記述子では、回帰係数のスケールも異なってくるためである。
決定木の変数重要度とは何か
決定木の場合は、変数重要度を表す指標はいくつか存在する。しかし、gini不純度を用いた重要度が最も一般的であると言える。
gini不純度とは
gini不純度とは、ノードごとにラベルをどのくらい分類できていないかを示す指標となっている。あるノードに関するgini不純度は、以下の式で定義することができる。

上の式から、例えば、ノードにおいて完全にサンプルが分類されている場合は、gini不純度は0になることがわかるだろう。
変数の重要度
gini不純度を下に変数重要度を計算することができる。もう少し具体的に言うと、重要度は、ある特徴量で分割するとどれくらいgini不純度を下げられるのかを意味している。ある特徴量j に関する重要度は以下で定義することができる。

これらの説明は、以下のサイトがわかりやすいと思ったのでurlを載せておく。
yolo-kiyoshi.com
多重共線性
ただし、これら変数の分析を行う際には、変数同士の多重共線性に注意する必要がある。多重共線性とは、記述子同士の相関係数が高い場合に起こってしまう現象のことをいう。記述子どうし相関係数が高いと回帰係数や変数重要度が全く安定しないという現象が起きてしまう。つまり、回帰を行うたびに全く異なる係数・重要度が獲得されてしまい、その回帰係数・重要度は信頼できないものとなってしまう。 このような対処方法としては、事前に記述子同士の相関係数を確認し、そのような記述子を除外するなどの対処が必要となってくる。わかりやすい解説を行っているサイトのurlを以下に載せておく。
xica.net
toukeier.hatenablog.com
note.com
実装
モデル作成のための準備
モデルを作るために、ライブラリのインポート、データの読み込みが必要なのでいつもの通りそれらの準備をする。使用するデータは、Materials Project中のLi-O系化合物約6000件に関するものである。
今回は、目的変数を生成エネルギー、記述子を元素特性の統計量(約40個)を使用している。
詳しくは、前の記事を参考にしてください。
taruto-mateinfo.hatenablog.com
# データ加工・処理・分析ライブラリ import numpy as np import pandas as pd # 可視化ライブラリ import matplotlib.pyplot as plt %matplotlib inline from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split #RMSEを算出するための関数を定義 def rmse(y_true,y_pred): return np.sqrt(mean_squared_error(y_true,y_pred)) #変数の重要度をプロットするための関数 def feature_plot(df_coef,labelsize=18): plt.figure(figsize=(14,6)) plt.bar(df_coef['features'],df_coef['coef'], label=model.__class__.__name__, color='Black', linestyle=':') plt.ylabel('Feature importance (coefficient)',fontsize=labelsize) plt.xlabel('Features',fontsize=labelsize) plt.xticks(rotation=90) plt.tick_params(labelsize=labelsize) plt.title('Coefficient analysis ({})'.format(model.__class__.__name__),fontsize=labelsize*1.2) plt.show() #Li-O系の化合物データに関する記述子、目的変数が入っているファイル名 filename='./Li_O_atom2vec_ave_var_with_form_ene_per_atom.csv' df = pd.read_csv(filename,index_col=0) X = df.drop(['mp-id','formation_energy_per_atom'],axis=1) y = df['formation_energy_per_atom'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=777)
線形回帰の係数分析
まずは、線形回帰の変数の分析である。回帰係数を分析するためには予測式を作成しなければならないので最初にフィッティングを行う。 その後、回帰係数の分析を行っている。
from sklearn.linear_model import Ridge #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html # スケーリング(標準化) from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) model = Ridge(alpha=1.0) model.fit(X_train_std, y_train) y_train_pred = model.predict(X_train_std) y_test_pred = model.predict(X_test_std) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) coef=model.coef_#回帰係数の取得 features_columns=X.columns df_coef = pd.DataFrame({'features':features_columns,'coef':coef}) df_coef=df_coef.sort_values('coef',ascending=False) df_coef.to_csv('{}_coef.csv'.format(model.__class__.__name__))#回帰係数をcsvファイルに書き出している feature_plot(df_coef)
>RMSE(train):0.345 RMSE(test):0.340(出力)

AN(元素番号)の平均値が正に効いていることがよくわかる。またAW(原子量)とPQN(周期番号)の平均が大きく負に効いていることもわかった。このようにして回帰係数を分析することが可能である。
ただし、これらの変数間で相関関係があるものが含まれていると予想される(例えば、原子番号と原子量は同じような変動をするので、間違いなく相関がある)。したがって、多重共線性があると考えられる。よって、本気で分析をしたい場合は、事前に変数同士の相関関係を調べる、 Lasso, PLSなどを用いて変数を削減しておく必要があったり、検定を行ったりする必要もある(ここまでちゃんとやっているマテリアルズ・インフォマティクスの研究は少ないが)。
基本的に、線形モデル(Lasso, 重回帰)であれば同じような方法"model.coef_"で回帰係数を取り出すことができる。
Random Forestによる変数重要度
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(max_depth=15,n_estimators=500, random_state=777) model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) coef = model.feature_importances_#変数重要度の取得 features_columns=X.columns df_coef = pd.DataFrame({'features':features_columns,'coef':coef}) df_coef=df_coef.sort_values('coef',ascending=False) df_coef.to_csv('{}_coef.csv'.format(model.__class__.__name__)) feature_plot(df_coef)>RMSE(train):0.088 RMSE(test):0.211(出力)
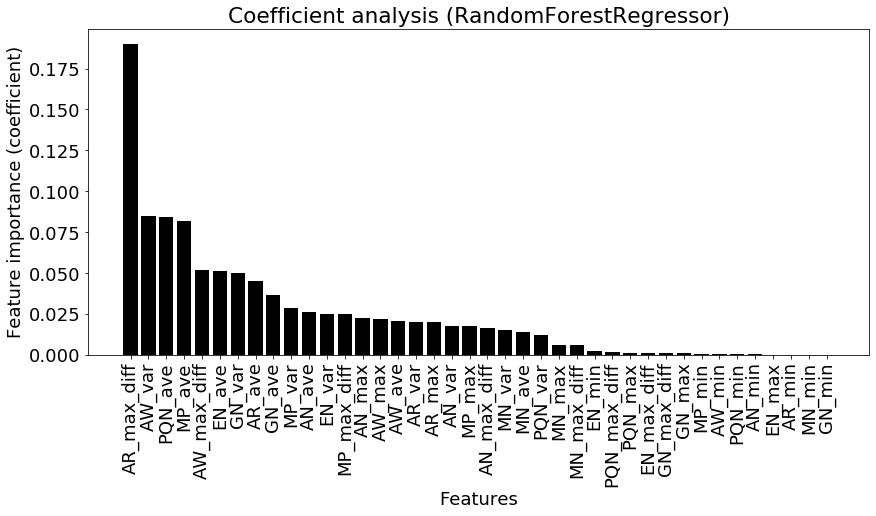
このscikit-learnを用いた場合は、gini不純度を元に変数重要度を算出している。
今回の分析で元素半径の最大差が最も重要度が高いことがわかる。次いで、原子量の平均値、周期番号の平均値が効いていると示されている。このように決定木のアンサンブルを使用したランダムフォレストは、精度も高くある程度変数の重要度を把握できるため、非常に多くの場面で使用されている。
ただし、線形回帰の回帰係数と同様に、この変数重要度に関しても多重共線性の影響が含まれているため、注意が必要である。