マテリアルズ・インフォマティクスのモデル評価とハイパーパラメータチューニング
本記事の概要
この記事では、以下について解説していく。
- モデルの評価方法(保留法と交差検証法)
- ハイパーパラメータチューニングの方法(グリッドサーチ)
本記事ではマテリアルズインフォマティクスで最もよく使用される教師あり学習のモデル評価方法とハイパーパラメータチューニングについて具体的なコードを交えて紹介していく。言語はPythonライブラリは、Scikit-learnを使用する。
この基礎は、Pythonをある程度習得した人向けの記事となっている。
目次:
モデルの評価方法
前回の記事では、学習データとテストデータに分けてモデルを作成し、評価を行った。
このようにモデルの学習に使用しないデータを予め準備し、モデルの性能を確認することは非常に重要である。これは、機械学習モデルは既存のデータに対して高い精度を達成するだけではなく、未知データに対しても高い性能を発揮することが重要となるからである。したがって、この章では、適切なモデル評価方法を学ぶこととする。
過学習とは:
ここで、機械学習でよく問題に挙げられる、過学習について説明する。機械学習では、学習に用いたデータに対しては高い精度が達成できるが、未知のデータに対しては精度が劣ってしまう現象を過学習という。機械学習は、基本的に過学習との戦いであると言われているくらいである。これを防ぐために、今回紹介する保留法や交差検証法を用いて評価を行う必要がある。
保留法と交差検証法
この節では、最もよく使用される評価手法である保留法と交差検証法を学ぶ。
保留法
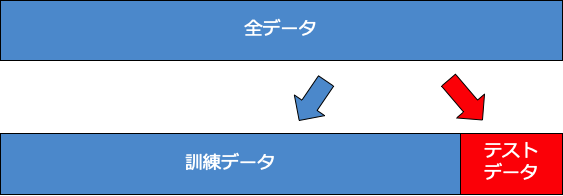
保留法(ホールドアウト法)とは、前回の記事でも行った通り、データを学習データとテストデータの二つにランダムに分割し、学習データを用いてモデルを作成してテストデータでモデルを評価する方法である。
保留法は、非常にシンプルな評価方法であるが、データ数が十分に大きい場合は、モデルの評価方法として十分に機能する。しかし、データ数が非常に少ない場合は、テストデータに偶然都合の良いデータが多くなってしまい、モデルが課題評価されてしまうという問題が生じる。下に保留法のイメージを示す。
交差検証法
交差検証法(Cross-validation)とは、上記の保留法の問題を解決できる手法である。これは、学習データと検証データを何度も入れ変えて評価する方法である。交差検証法で最もよく衣装っされるのがk分割交差検証法(K-fold cross-validation)である。この手法では、データをk個のブロックにランダムに分割し、k個のうち1つのブロックを検証データ、残りのk-1個を学習データとして学習する。 k分割交差検証法のイメージを下に示す。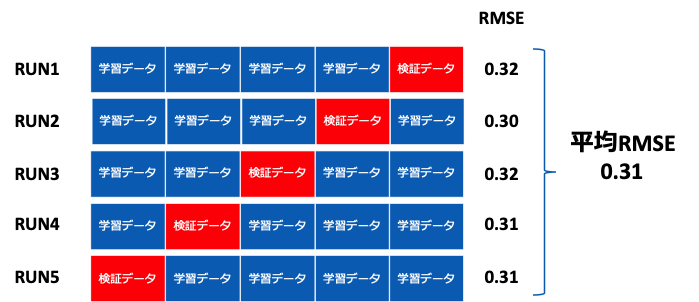
k分割交差検証法の実装準備
ここでは、Random Forestを用いて実際にk分割交差検証法を行う。扱うデータは前記事と同じくLi-O系の化合物に関する生成エネルギーの予測である。これを行うために、事前に以下を実行しておく。# 実装前の準備 # データ加工・処理・分析ライブラリ import numpy as np import pandas as pd # 可視化ライブラリ import matplotlib.pyplot as plt %matplotlib inline import sklearn # 機械学習ライブラリ import pickle # 予測モデルの保存をするためのライブラリ from sklearn.metrics import mean_squared_error #RMSEを算出するための関数を定義 def rmse(y_true,y_pred): return np.sqrt(mean_squared_error(y_true,y_pred)) #MAEを算出するための関数を定義(今回は使用しないがテンプレートとして残す) def mae(y_true,y_pred): return np.abs(y_true-y_pred).mean() #予測値と真値を比較するためのグラフを作成する関数を定義 def plot(y_true,y_pred): xx = np.arange(-4.0, 0.5, 0.1) plt.plot(xx,xx,linestyle='--') plt.scatter(y_true,y_pred) plt.xlabel('True values') plt.ylabel('Predicted values') plt.show() #Li-O系の化合物データに関する記述子、目的変数が入っているファイル名 filename='./Li_O_atom2vec_ave_var_with_form_ene_per_atom.csv' df = pd.read_csv(filename,index_col=0) #保留法による訓練データとテストデータの作成 from sklearn.model_selection import train_test_split X = df.drop(['mp-id','formation_energy_per_atom'],axis=1) y = df['formation_energy_per_atom'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=777)
k分割交差検証法の実装
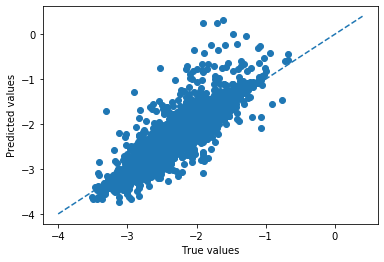
今回は、sklearn.model_selection.KFoldを用いてk分割交差検証法を行う。 n_split=5とすると、訓練データに対して5分割でk分割交差検証法を行うことになる。"for train_index,test_index in kf.split(X_train):" とすることで、ランダムに訓練データ用のインデックスと、検証データ用のインデックスが選択される。 そして、5分割の場合それが5回繰り替えされる。 このような交差検証を行うと、全てのトレーニングデータが必ず1度検証データになる。したがって、検証データになったときの予測値を集めていくことでデータ全体を使ってより検証精度を算出できる。このため、小さいデータセットであっても検証の信頼性が増すと言える。 また検証データに対する予測値のプロットも作ることができる。
from sklearn.ensemble import RandomForestRegressor #Ref.) https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html from sklearn.model_selection import KFold kf = KFold(n_splits=5,shuffle=True,random_state=777)#k分割交差検証法用のインスタンスを作成 pred_validation = np.array([])# 検証データになった際の予測値を集めるためのnp.array ans_validation = np.array([])# 検証データになった際の目的変数を順番通りに集めるためのnp.array pred_train = np.array([])# 訓練データになった際の予測値を集めるためのnp.array ans_train = np.array([])# 訓練データになった際の目的変数を順番通りに集めるためのnp.array for train_index,test_index in kf.split(X_train): X_tr = X_train.iloc[train_index] y_tr = y_train.iloc[train_index] X_va = X_train.iloc[test_index] y_va = y_train.iloc[test_index] model = RandomForestRegressor(max_depth=15,n_estimators=100, random_state=777) model.fit(X_tr,y_tr)#ここで、訓練データを学習 pred_val_y = model.predict(X_va)#ここで、検証データを予測 pred_tra_y = model.predict(X_tr) pred_validation = np.append(pred_validation,pred_val_y) ans_validation = np.append(ans_validation,y_va) pred_train = np.append(pred_train,pred_tra_y) ans_train = np.append(ans_train,y_tr) val_rmse = rmse(pred_validation,ans_validation)#検証データの平均RMSEを算出 tra_rmse = rmse(pred_train,ans_train) print('(Cross validation)Train RMSE: {}, Valid RMSE: {}'.format(round(tra_rmse,3),round(val_rmse,3))) #プロットを描く plot(pred_validation,ans_validation)>(Cross validation)Train RMSE: 0.105, Valid RMSE: 0.223(出力)
ハイパーパラメータチューニング(精度向上のためモデアプローチ)
グリッドサーチ
本節では、そもそものモデルの性能を向上させるための手法である、ハイパーパラメータチューニングを紹介する。 今回は、最適化手法であるグリッドサーチを用いたチューニングについて実装する。 各機械学習アルゴリズムは、それぞれ固有のハイパーパラメータを持っている。これらは、学習により更新されるのではなく、人が予め決定する必要がある。 Random Forestであれば、決定木の深さ、決定木をいくつ集めるのかなどが存在する。グリッドサーチでは、チューニングしたいパラメータ全ての組み合わせに対して交差検証を行い、最も性能の高いパラメータの組み合わせ探索する。 今回は、3つのハイパーパラメータについてチューイングを行った。それぞれのパラメータは2つのずつ候補があるので、これらの全通り数は、8通りとなる。これら全ての通り数を実行するためにfor文を回している。from sklearn.ensemble import RandomForestRegressor #Ref.) https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html #以下、調節するハイパーパラメータ 。================= #通り数を増やすと結構時間がかかるので注意 parameters= {'max_depth': [15,30], #木の深さ 'min_samples_leaf': [1,2], #枝の先の最小サンプル数 'n_estimators':[10,100], #木の数 } #=========================================== best_val_rmse = np.inf for n_estimators in parameters['n_estimators']: for max_depth in parameters['max_depth']: for min_samples_leaf in parameters['min_samples_leaf']: pred_validation = np.array([]) ans_validation = np.array([]) pred_train = np.array([]) ans_train = np.array([]) for train_index,test_index in kf.split(X_train): X_tr = X_train.iloc[train_index] y_tr = y_train.iloc[train_index] X_va = X_train.iloc[test_index] y_va = y_train.iloc[test_index] model = RandomForestRegressor( max_depth=max_depth, min_samples_leaf=min_samples_leaf, n_estimators=n_estimators, n_jobs=-1, random_state=777) model.fit(X_tr,y_tr) pred_val_y = model.predict(X_va) pred_tra_y = model.predict(X_tr) pred_validation = np.append(pred_validation,pred_val_y) ans_validation = np.append(ans_validation,y_va) pred_train = np.append(pred_train,pred_tra_y) ans_train = np.append(ans_train,y_tr) val_rmse = rmse(pred_validation,ans_validation) tra_rmse = rmse(pred_train,ans_train) if val_rmse < best_val_rmse: #検証精度が改善した場合、以下の変数を上書きする。 best_val_rmse = val_rmse best_tra_rmse = tra_rmse best_predict_val = pred_validation best_predict_val_ans = ans_validation best_params={ 'max_depth':max_depth, 'min_samples_leaf':min_samples_leaf, 'n_estimators':n_estimators, 'random_state':777 'n_jobs':-1 } print('max_depth: {}, min_samples_leaf:{}, n_estimators:{}, train RMSE: {}, valid RMSE: {}'.format(max_depth,min_samples_leaf,n_estimators,round(tra_rmse,3),round(val_rmse,3))) print('Best params:') print('max_depth: {}, min_samples_leaf:{}, n_estimators:{}, train RMSE: {}, valid RMSE: {}'.format(best_params['max_depth'],best_params['min_samples_leaf'],best_params['n_estimators'],round(best_tra_rmse,3),round(best_val_rmse,3))) #診断プロットを描く plot(best_predict_val_ans,best_predict_val)>(出力) max_depth: 15, min_samples_leaf:1, n_estimators:10, train RMSE: 0.107, valid RMSE: 0.234
max_depth: 15, min_samples_leaf:2, n_estimators:10, train RMSE: 0.123, valid RMSE: 0.233
max_depth: 30, min_samples_leaf:1, n_estimators:10, train RMSE: 0.099, valid RMSE: 0.231
max_depth: 30, min_samples_leaf:2, n_estimators:10, train RMSE: 0.118, valid RMSE: 0.232
max_depth: 15, min_samples_leaf:1, n_estimators:100, train RMSE: 0.091, valid RMSE: 0.223
max_depth: 15, min_samples_leaf:2, n_estimators:100, train RMSE: 0.11, valid RMSE: 0.225
max_depth: 30, min_samples_leaf:1, n_estimators:100, train RMSE: 0.082, valid RMSE: 0.221
max_depth: 30, min_samples_leaf:2, n_estimators:100, train RMSE: 0.105, valid RMSE: 0.224
Best params:
max_depth: 30, min_samples_leaf:1, n_estimators:100, train RMSE: 0.082, valid RMSE: 0.221
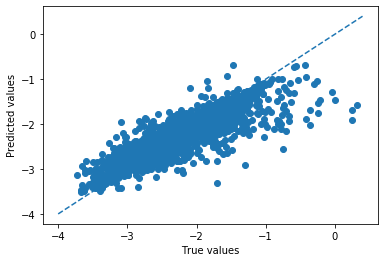
このグリッドサーチの結果から、
”max_depth: 30, min_samples_leaf:1, n_estimators:100”がベストなハイパーパラメータの組み合わせであることがわかる。 今回はチューニング方法としてグリッドサーチを用いたが、最適化する際にランダムサーチやベイズ最適化を用いる場合もある。パラメータの組み合わせ数が多すぎる場合は、これらの手法で最適化した方が良いと言えるだろう。
テストデータの予測
先ほどのパラメータを用いて、テストデータ(最終評価用データ)についての予測を行う。model = RandomForestRegressor(**best_params) #最も良かったハイパーパラメータをモデルにセットする model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) plot(y_test,y_test_pred)>RMSE(train):0.079 RMSE(test):0.212(出力)
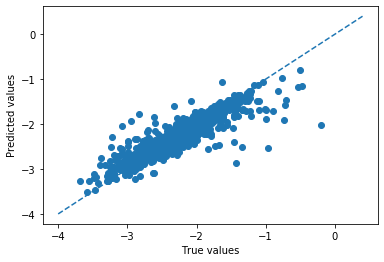
テストデータに対する予測精度が、検証精度と大きく変わらないことから過学習は生じていないことが確認できる。 また、この時の予測精度が0.2 eV/atom程度であることがわかった。第一原理計算による精度は0.01eV / atom程度であるため、それと比較するとかなり劣っていることがわかる。しかし、組成情報だけを用いて一瞬で予測が可能であることを考えると、ある程度有用に活用できるかもしれないと考えることができる。