マテリアルズインフォマティクスのための、機械学習の基礎(教師あり学習・回帰)
本記事の概要
この記事では、以下について解説していく。
本記事ではマテリアルズインフォマティクスで最もよく使用される教師あり学習の具体的手法について紹介する。
この記事を読むことで、機械学習モデル構築の基本を理解し、正しく実行できることを目指す。PythonやPandas、Numpyの使い方については、今回の記事では解説しない。 また、この記事のコードをテンプレートのように使い回すことも可能である。
本記事では、Materials ProjectからLi-O系化合物の生成エネルギーを取得し(取得方法については、解説していない)、このデータを用いて回帰予測を行っている。今回は、Jupyter notebookを使用してコードを書いている。
目次:
機械学習の概要
機械学習とは
おそらく、この記事を読む人は機械学習とはなんなのかわかっている人が多いと思うが、念のため説明する。
機械学習(machine learning)は、何かしらの目的を達成するための知識や行動を、データを読み込ませることで機械に獲得させるための技術である。機械学習は大きく、教師あり学習(supervised learning)、教師なし学習(unsupervised learning)、強化学習(reinforcement learning)に分けられる。本記事では教師学習についてのみ解説する。
機械に読み込ませて知識や行動を獲得させるために使うデータのことを訓練データと言う。 教師あり学習と教師なし学習の違いは、訓練データに、目的変数や説明変数(後述)があるかどうかである。もっと簡単に言うと、正解のデータがあってそれを与えるのが教師あり学習、そうでないのが教師なし学習となる。現状マテリアルズ・インフォマティクスの分野では、この教師あり学習が最もよく使用されている。
教師あり学習の手法
教師あり学習は、さらに2種類の予測が可能である。
- 回帰予測:数値を予測する
例)バンドギャップの値を予測、生成エネルギーの予測、硬度の予測など
- 分類予測:事前に定義されたラベルに分類予測する
例)絶縁体 or 導体の分類予測、硬度が高い or 低いの分類予測など
これらの予測に対して、教師あり学習には多くの手法がある。しかし、どのモデルを使用するかは、何を目指してそのモデルを構築しているのかで異なってくる。
解釈性(なぜそのような結果になったのか)を重視したい場合には、線形回帰(重回帰・Ridge回帰・Lasso回帰)や決定木など比較的簡単な予測モデルを使用することが多い。一方、高い予測精度を目指している場合には、決定木のアンサンブル(Random Forest)や深層学習を用いることが多い。そして、それらの予測精度を比較することで予測モデルを決定する必要がある。
使用するライブラリのインポート
本記事では、Scikit-learnと言う機械学習ライブラリを使用する。
Scikit-learnの公式ドキュメントには、詳細な使い方などが紹介されているので参考にすると良い。
公式ドキュメント:
scikit-learn.org
では、使用するライブラリをインポートする。
# データ加工・処理・分析ライブラリ import numpy as np import pandas as pd # 可視化ライブラリ import matplotlib.pyplot as plt %matplotlib inline #Jupyter notebook用 # 予測モデルの保存をするためのライブラリ import pickle
データの読み込み
ここでは、csv形式(コンマ区切り)のファイルを読み込んで表示する。
#Li-O系の化合物データに関する記述子、目的変数が入っているファイル名 filename='./Li_O_atom2vec_ave_var_with_form_ene_per_atom.csv' df = pd.read_csv(filename,index_col=0) df.head()

今回使用するデータは、Materials Project中に登録されている。Li - O系の組成物(約6000件)である。
データの一番先頭列には、Materials Projectにて各化合物に割り当てられているMaterial IDと組成を含んだ情報が示されている。
その後40列には、Li - O系の化合物に関する組成情報から作成した様々な組成記述子を載せている(簡単な自作組成記述子となっている)。 化合物中に存在する元素に関する特性を化合物全体の平均値、分散、最大値、最小値、最大差を取っている。
最後に、Materials Projectに登録されている物性であるFormation energy per atomが入っている。
一つの組成に対して複数の構造(多形)がある場合は、最も安定な構造(分解エネルギーが最小)となる化合物のFormation energy per atomを取得している。
予測モデルを作成・評価するための準備
訓練データ・テストデータの作成
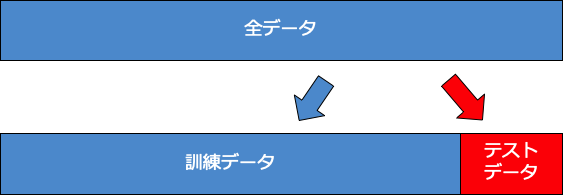
今回は、保留法を用いてデータの分割を行う。保留法のイメージを下に載せておく。
保留法は、単純にいテストデータを訓練データとテストデータに分割する方法である。この際のデータの選択のされ方はランダムになっている。
X = df.drop(['mp-id','formation_energy_per_atom'],axis=1) y = df['formation_energy_per_atom'] #データの分割 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=777)
予測精度確認のための関数を事前に定義(RMSE,MAE,グラフ描画)
from sklearn.metrics import mean_squared_error #RMSEを算出するための関数を定義 def rmse(y_true,y_pred): return np.sqrt(mean_squared_error(y_true,y_pred)) #MAEを算出するための関数を定義(今回は使用しないがテンプレートとして残す) def mae(y_true,y_pred): return np.abs(y_true-y_pred).mean() #予測値と真値を比較するためのグラフを作成する関数を定義 def plot(y_true,y_pred): xx = np.arange(-4.0, 0.5, 0.1) plt.plot(xx,xx,linestyle='--') plt.scatter(y_true,y_pred) plt.xlabel('True values') plt.ylabel('Predicted values') plt.show()
予測モデルの作成・評価
重回帰
重回帰は最も簡単な回帰手法だろう。
重回帰では各記述子の係数を、予測値と目的変数の二乗誤差が最小になるように推定される。 これ以上の説明はいらないと思うので割愛する。
from sklearn.linear_model import LinearRegression #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html model = LinearRegression()# 重回帰クラスの初期化 model.fit(X_train, y_train)#学習 y_train_pred = model.predict(X_train)# 訓練データに対する予測 y_test_pred = model.predict(X_test)# テストデータに対する予測 train_rmse = rmse(y_train,y_train_pred)# 訓練データに対するRMSE test_rmse = rmse(y_test,y_test_pred)# テストデータに対するRMSE print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse))# RMSEを表示 # 予測式の保存を行う。保存することで後からこの式を使用して予測することができる。 output_name='LinearRegression.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred) #テストデータに対する予測結果と、テストデータの真の値を比較するためのプロット
>RMSE(train):0.337 RMSE(test):0.327 (出力)

ある程度は、回帰予測ができていることが確認できる。図中の点線はy=xの直線を示しており、この線上にプロットが近づくほど、より正確な予測ができていることになる。
RIdge回帰
重回帰では、予測値と目的変数の誤差が最小化されるように学習が進んでいく。 一方、Ridge回帰では、回帰係数の二乗和も誤差に追加することで回帰係数が小さくなるように設計されている。
一般に回帰係数が大きいモデルでは、インプットの少しの動きで予測値が大きく変動するようになってしまう。 このように入力値に非常に敏感なモデルは、訓練データに対しては、非常に良い精度を示すが、未知のデータに対してはうまく当てはまらない場合があり、過学習が起きてしまうリスクがあると言える。 そこで、回帰係数の二乗和も誤差に追加することで、過学習防止を狙っているモデルがRidgeである。 一方、回帰係数の絶対和を誤差に追加するモデルは、Lassoと呼ばれる。
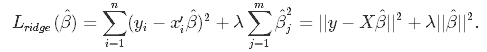
from sklearn.linear_model import Ridge #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html model = Ridge(alpha=1.0) model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='Ridge.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.342 RMSE(test):0.335 (出力)

精度向上のためのアプローチ(スケーリング)
ここで予測精度を上げるためのアプローチの1つであるスケーリングについて紹介する。
このモデルでは、様々な記述子を使用しているが、それぞれの単位や大きさは異なっている。よって、このままだとモデルの学習が値の大きな変数に引っ張られ、値の小さな変数の影響が小さくなる懸念がある。
そこで、それを防ぐため、記述子の標準化を行う(スケーリングの方法はいくつか存在しているが、最もよく使用されているのは標準化だと思う)
標準化とはスケーリングの一種で、データの各値から変数列の平均を引き、標準偏差で割る。こうすることで変数間の単位が消え、数値の大小と意味するところが合致します。データを標準化するにはStandardScalerを使用する。
このスケーリングは、基本的に決定木系のモデル以外に関してはうまく作動するため、基本的に標準化を行った記述子を使用した方が精度が上がりやすい。
ただし、元々規格化が行われている記述子に対してさらにスケーリングを行うと精度低下を招いてしまう場合もあるので、その場合は注意が必要。
スケーリング後のRidge回帰の結果
# スケーリング(標準化) from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) model = Ridge(alpha=1.0) model.fit(X_train_std, y_train) y_train_pred = model.predict(X_train_std) y_test_pred = model.predict(X_test_std) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='Ridge_std.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
> RMSE(train):0.345 RMSE(test):0.340(出力)

今回の場合は、残念ながら精度改善は見られなかった。必ずしもスケーリングによって精度が改善されるわけではないが、試す価値は大いにある。
Lasso回帰
先ほど説明したRidgeと似ているLasso回帰である。
回帰係数の絶対和を誤差に追加する事で、回帰係数が小さくなるように設計されている。
from sklearn.linear_model import Lasso #https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html # 重回帰クラスの初期化と学習 model = Lasso(alpha=0.0001) model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) # 決定係数を表示 print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='Lasso.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.350 RMSE(test):0.346(出力)

決定木回帰
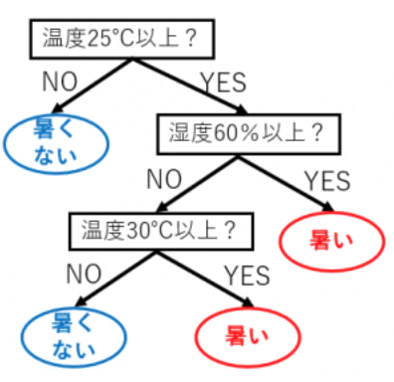
決定木によるモデルは、各記述子に対して条件分岐を繰り返して予測を行う方法である。Yes or No問題を各サンプルに対して問うようなイメージである。
例えば、温度と湿度のデータから、暑く感じられるか、そうではないかといったことを分類予測する場合、以下のような決定木を作成するようにな(参考)。
from sklearn.tree import DecisionTreeRegressor model = DecisionTreeRegressor(max_depth=15, random_state=777) model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='DecisionTreeRegression.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.062 RMSE(test):0.288 (出力)

RandomForest回帰
Randon Forestは、上記の決定木モデルを複数個(今回の場合は500個)作り、それらの多数決(予測値の平均値)を取って最終的な予測モデルを作成するモデルである。決定木一つだけでは、実際の予測ではそこまで高い予測精度が出ないことが多い。しかし、これら決定木を複数個足し合わせることで非常に精度の高い予測モデルを作成することができる。まさに、「三人寄れば文殊の知恵」である。実際、マテリアルズ・インフォマティクスの分野でも非常に多くの適応事例が存在している。 またハイパーパラメータチューニイングも容易であることも一つの特徴である。
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(max_depth=15,n_estimators=500, random_state=777) model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='RandomForestRegression.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.088 RMSE(test):0.211(出力)

決定木のアンサンブルであるRandomForestは、今までの予測モデルと比較するとかなり精度が高いことが確認できる。
サポートベクトル回帰
サポートベクター回帰は、回帰予測の線を一本のせんで作成するのではなく、マージン(余白)を持った線で引く手法である。概要は、以下の画像に示す。
大規模な学習データに対しては、非常に時間がかかってしまうため、中規模以下のデータに対して適応することが多い。

from sklearn.svm import LinearSVR #https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVR.html model = LinearSVR() model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='LinearSVR.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):3.447 RMSE(test):4.236(出力)

サポートベクトルマシンの場合、スケーリングを行った方が精度が改善する場合がある。 スケーリングを行って再度学習・予測してみる。
model = LinearSVR() model.fit(X_train_std, y_train) y_train_pred = model.predict(X_train_std) y_test_pred = model.predict(X_test_std) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='LinearSVR_std.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.352 RMSE(test):0.339(出力)

今回の場合は、 スケーリングにより明らかに精度が向上していることがわかる。
カーネルサポートベクトル回帰
元々の空間では、複雑だったデータ分布が高次元(カーネルより作り出された空間)においては単純な分布になる場合がある。 KernelSVRでは、データに対してカーネルを適応し、高次元空間に射影する。 その後、一つ前のセクションで行ったSVRにより回帰を行う。 カーネルとしては、しばしばRBFカーネルが使用されることが多い。カーネルによる高次元化の例を以下に示す。(参考)

from sklearn.svm import SVR # 決定木クラスの初期化と学習 model = SVR(kernel='rbf') model.fit(X_train_std, y_train) # スケーリング後の記述子を学習する y_train_pred = model.predict(X_train_std) y_test_pred = model.predict(X_test_std) train_rmse = rmse(y_train,y_train_pred) test_rmse = rmse(y_test,y_test_pred) print('RMSE(train):{:.3f} RMSE(test):{:.3f}'.format(train_rmse,test_rmse)) output_name='KernelSVR_std.pickle' with open(output_name,mode='wb') as fp:#保存するファイルを準備している。 pickle.dump(model,fp)#ここで、予測式を保存している plot(y_test,y_test_pred)
>RMSE(train):0.211 RMSE(test):0.230(出力)
